
发明人:于慧敏,曾奇勋
申请日期:2018-12-29
授权日期:2021-04-23
本专利对应产品、技术优势、性能指标:本发明公开了一种基于群组信息损失函数的行人重识别方法。该方法通过使用超图对训练样本的群组信息进行建模、学习和表达,提供了一种包含群组信息的损失函数。不同于以往行人重识别中重排序方法,该方法将群组信息引入神经网络的训练过程中。同时,该方法针对不同的基础网络结构,都能提升所训练特征的表达能力和鲁棒性。
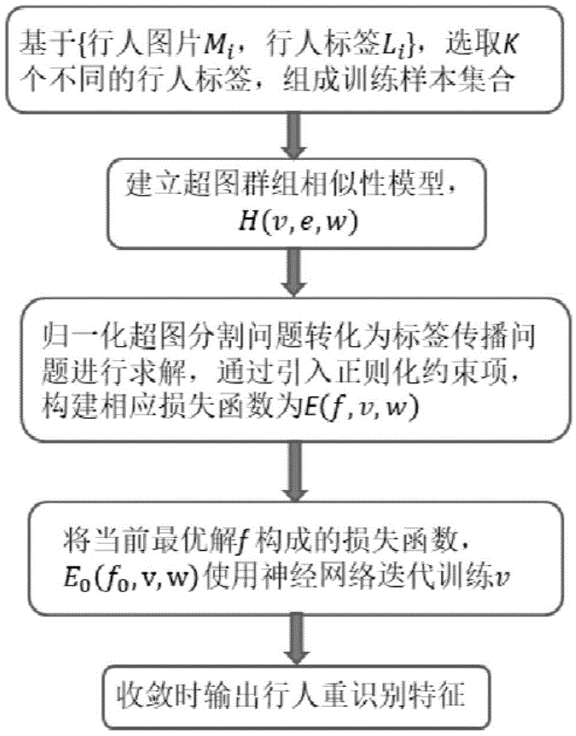
产业化前景描述:本发明提供了一种行人重识别方法。在视频监控、刑侦和智能交通等领域有重要应用前景。
发明人:于慧敏,丁洋凯
申请日期:2019-12-23
授权日期:2022-07-19
本专利对应产品、技术优势、性能指标:本发明可用于基于视频的人眼虹膜检测,能够高效定位人眼关键点的精定位以及虹膜外边界,精确性和鲁棒性较高,并且能达到实时处理的效率。
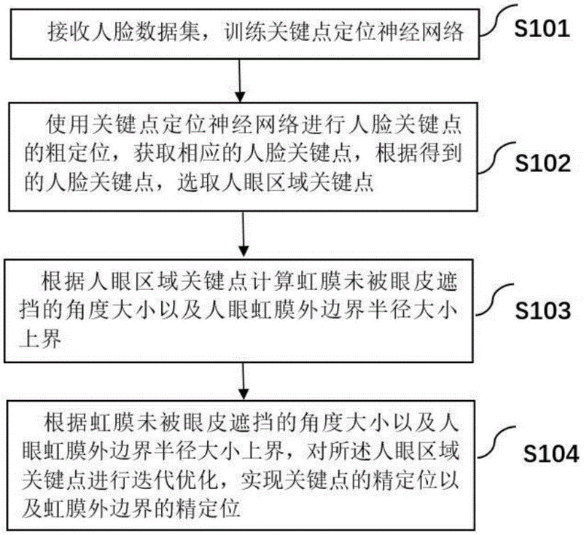
产业化前景描述:本发明可用于基于视频的高精度、高鲁棒和快速的人眼虹膜检测,有较好的产业化应用前景。
发明人:于慧敏,黄伟
申请日期:2019-12-18
授权日期:2022-10-04
本专利对应产品、技术优势、性能指标:发明了一种图像分割算法。该方法使用神经网络来自主自动地表达轮廓演化方向,将其应用于图像分割任务。相比于传统的主动轮廓分割模型和方法需要人工设定能量函数与演化方向,基于神经网络的轮廓演化可从数据和当前轮廓中自动学习和估计轮廓的演化方向。这种表达方法能够适应不同的初始轮廓,也克服了传统主动轮廓分割模型对于初始化轮廓非常敏感的问题。同时,由于本方法基于神经网络,此估计演化方向的网络能够根据需要自行拓展以适应不同的分割任务场景。
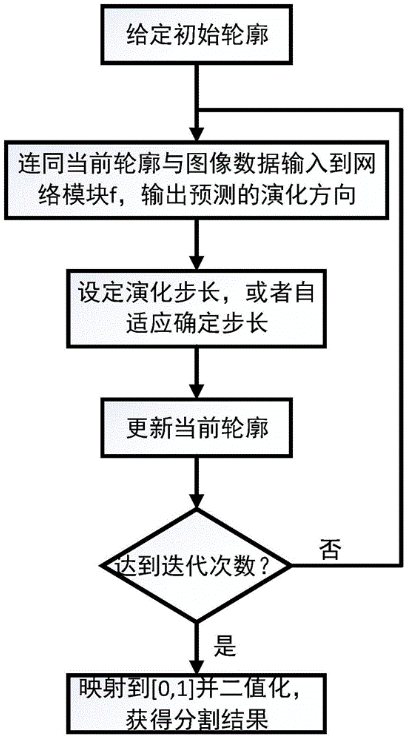
产业化前景描述:本发明可应用于图像分割任务。由于本方法基于神经网络自动学习和估计轮廓的演化方向,能够根据需要自行拓展以适应不同的分割任务场景。
发明人:于慧敏,李殊昭
申请日期:2020-01-14
授权日期:2022-05-03
本专利对应产品、技术优势、性能指标:本发明提供了一种基于视频的外观和运动信息同步增强的行人重识别方法,实际应用时仅需保留行人特征提取主干网络,无需增加网络复杂度和模型大小,就能够获得更高的行人重识别性能。增强后的主干网络特征在基于视频的行人重识别任务中获得了更高的准确率。
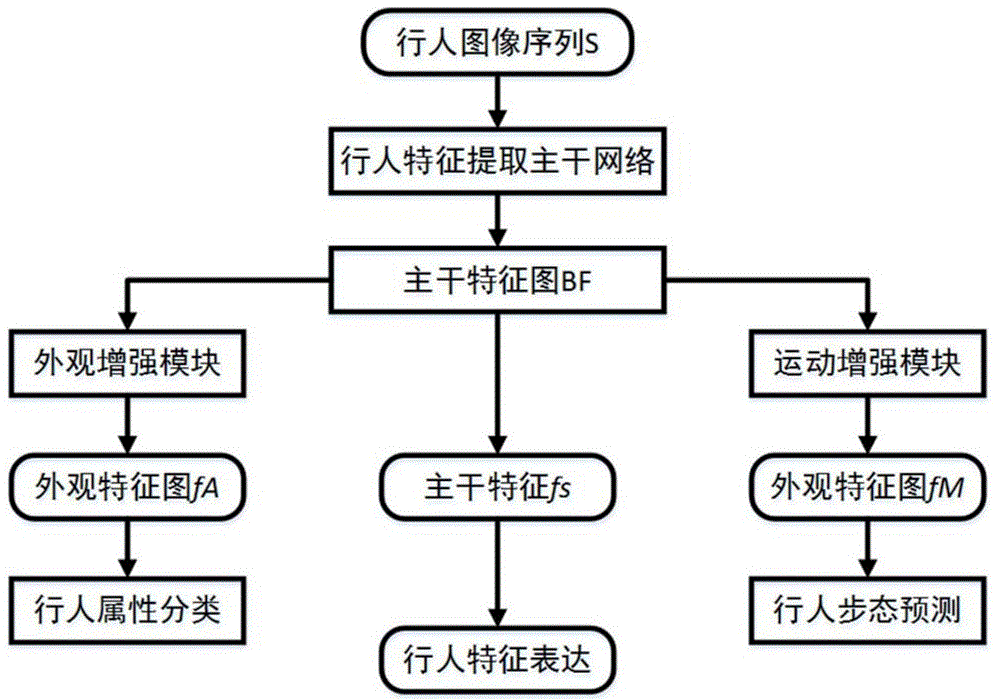
产业化前景描述:本发明提供了一种基于视频的行人重识别方法,在视频监控、刑侦、智能交通等领域有重要应用前景。
发明人:于慧敏,李殊昭,闫禹铭
申请日期:2021-08-16
授权日期:2023-09-19
本专利对应产品、技术优势、性能指标:设计了一种基于可靠价值样本和新身份样本挖掘的行人重识别域适应方法,提升了目标域模型的鲁棒性和泛化性。
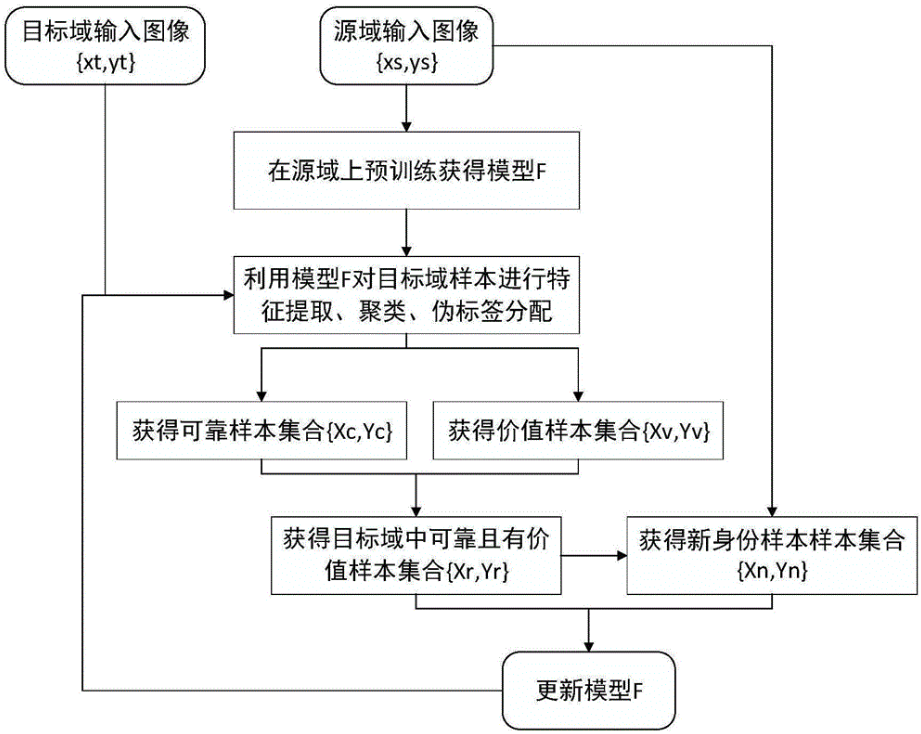
产业化前景描述:设计了一种行人重识别域适应方法,通过对目标域中已有样本的挖掘和未知样本的探索对目标域数据分布进行适应,提升了目标域模型的鲁棒性和泛化性。
发明人:于慧敏,李钰昊
申请日期:2020-02-25
授权日期:2022-07-15
本专利对应产品、技术优势、性能指标:本发明公开了一种3D手势估计算法。不同于以往的手势估计方法,该方法的目标是在低维隐含空间之间学习建立映射关系,使得学习难度降低。同时,该方法有效地利用了多任务学习机制,使得学习到的特征更加全面,鲁棒性和精度更高。
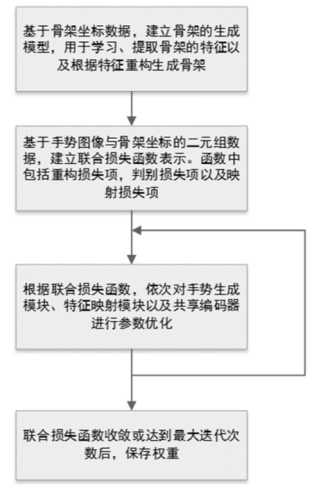
产业化前景描述:本发明可用于3D手势估计相关的应用。在人机交互、AR/VR等方面有重要应用。
发明人:于慧敏,厉佳男
申请日期:2020-05-07
授权日期:2023-11-24
本专利对应产品、技术优势、性能指标:提出了一种联合语义分割的场景深度补全方法,通过构建联合语义分割的网络模型进行场景深度补全,以及深度补全损失、语义分割损失和跨域边缘一致性损失,重点提升深度图在语义边缘区域的性能。
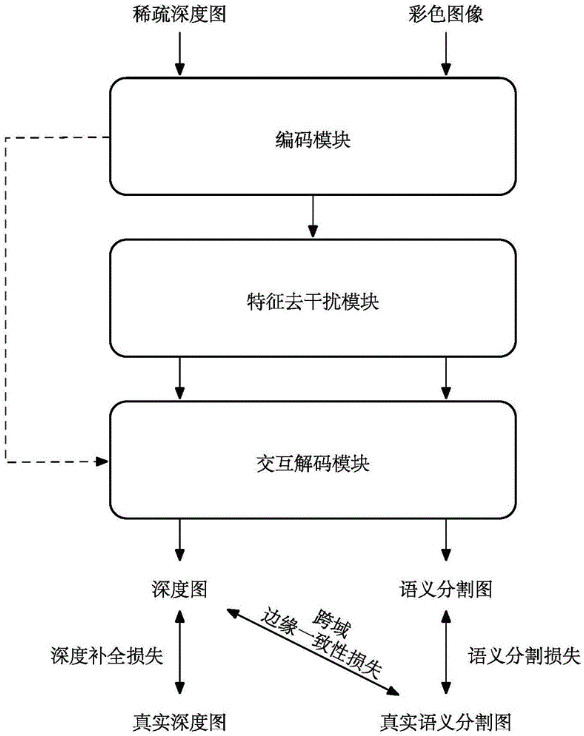
产业化前景描述:相比传统立体匹配或者运动恢复结构,没有很好的泛化能力,且需要海量数据来训练,本发明:
(1)提出一种对联合网络中的共享特征进行去干扰的方法,通过拆分和重组两个步骤,从共享特征中分别提取出对于各任务而言仅包含有利信息的特征,实现联合任务间信息去干扰。
(2)提出一种在联合网络的独立分支之间进行信息交互的策略,一方面,用语义分割相关特征对深度补全相关特征进行指导,另一方面,在深度补全相关特征和语义分割相关特征之间进行双向且有选择性的信息交互。
发明人:于慧敏,刘柏邑
申请日期:2020-12-16
授权日期:2023-01-10
本专利对应产品、技术优势、性能指标:如何根据一对不同角度的人脸RGB-D数据,精准估计出二者之间的相对姿态,并利用人脸相对姿态估计的应用场景,如注意力检测、行为分析、人机互动和视线追踪等,提高人机交互的质量和有效性。同时,如何设计不同结构的深度学习网络,对当前人脸的特征进行提取并回归角度,得到当前人脸的姿态。最后,如何利用点云来更准确地反映出物体表面的真实大小与形状结构,并且逐渐成为了计算机视觉领域的一种比较重要的数据结构。
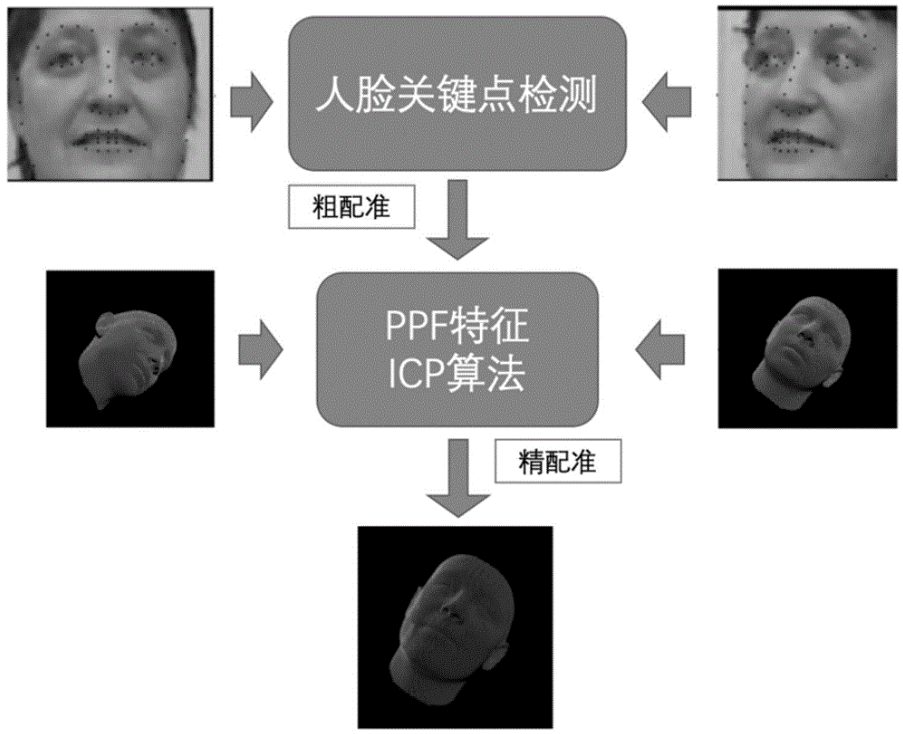
产业化前景描述:该专利文本提出了一种基于点云匹配的技术,通过实现点云匹配和相对姿态估计的融合,提高了精度。同时,通过对关键点的检测和初步匹配,为后续的迭代最近点过程提供了良好的初值,避免了算法朝着错误的方向迭代或无法收敛的可能性。此外,通过对人脸区域的裁剪,增强了匹配过程的鲁棒性,减少了无法收敛的可能性。最后,通过引入点对特征,减少了原始ICP算法中使用欧氏距离来寻找对应点的弊端,提高了点云匹配的准确性和效率。综上所述,该技术提高了点云匹配的精度和效率,具有较好的应用前景。
发明人:于慧敏,刘柏邑,龙阳祺
申请日期:2021-05-28
授权日期:2023-11-24
本专利对应产品、技术优势、性能指标:不同于之前的深度估计方法,该方法使得姿态估计以及深度估计均保持时域稳定,并且利用注意力机制将姿态特征与深度特征融合,使得深度图在时域上保持平滑的同时大幅度提高深度估计的精度。
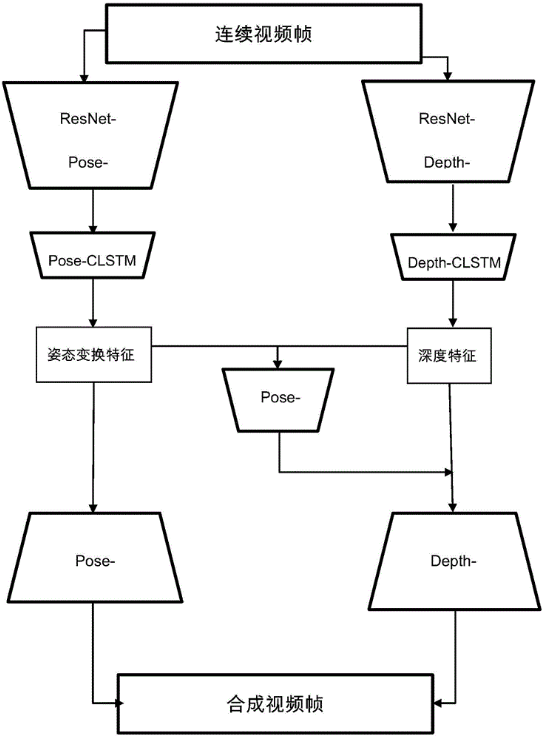
产业化前景描述:可用于需要单目视频深度估计方面的应用,包括相关3D感知、建模等方面的应用,特别是结合姿态估计和需要较高时域稳定稳定性的相关应用。
发明人:于慧敏,徐晨锋,龙阳祺
申请日期:2021-04-28
授权日期:2022-07-15
本专利对应产品、技术优势、性能指标:本发明提供了一种基于视频的基于多帧注意力的自监督深度估计方法。其中分为深度估计网络和相机姿态估计网络两路网络分别估计目标帧的深度以及预测相机运动。本发明不仅可以大幅提高深度估计的各项精度,还能提高算法对于深度估计的时域一致性。

产业化前景描述:本发明提供了一种基于视频的自监督深度估计算法。不仅可以大幅提高深度估计的各项精度,还能提高算法对于深度估计的时域一致性,在3D感知、3D建模、AR/VR等方面有重要应用。
发明人:于慧敏,张净
申请日期:2019-12-18
授权日期:2022-04-01
本专利对应产品、技术优势、性能指标:本发明公开了一种基于区域关系建模和信息融合建模的表情识别方法。不同于之前的识别方法,该方法模拟了两个层次的信息建模,最大化提取表情相关特征的同时能够抑制噪声信息。并且通过自动编码器生成表情特征模式图,增强了表情识别的可解释性。

产业化前景描述:本发明提供了一种表情识别方法,在视频监控系统、视觉应用和人机交互等领域有重要应用前景。
信息安全设备制造;云计算与大数据服务;人工智能软件;记录媒介复制;信息处理和存储支持服务;数字文化创意技术设备;智能消费相关设备制造
前述成果已申请专利并获得授权。
□样品、实验阶段
□小批量生产、工程应用阶段
☑试生产、应用开发阶段
□批量生产、成熟应用阶段
于慧敏教授,博士生导师,主要研究视频智能信息处理理论与应用、计算机视觉、医学影像分析与处理、数字信号处理理论与技术。
浙大工研院成果转化服务中心,0571-88982927。
注:所有成果技术资料来自研究团队,未经授权,请勿转载!
咨询授权请联系:0571-88982927
电话:0571-88982935
传真:0571-88982801
地址:浙江省杭州市西湖区西园八路3号浙大紫金科创小镇E1楼六楼
