
发明人:刘鹏,耿洋,史册
申请日期:2015-01-19
授权日期:2017-10-31
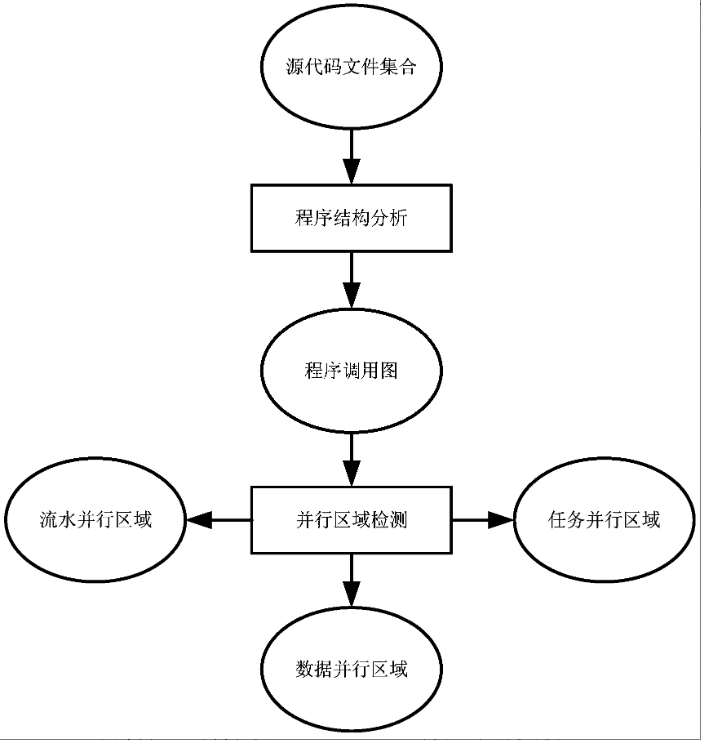
本专利对应产品、技术优势、性能指标:本发明公开了一种C程序并行区域的检测方法,其特征在于,包括以下步骤:(1)对源文件中系统头文件以外的部分进行预编译;(2)将预编译后的源代码连同系统头文件进行编译并进行动态分析;(3)向预编译后得到的源代码中插入动态分析结果,得到中间文件;(4)对所述中间文件进行静态分析,生成程序调用图;(5)结合所述程序调用图,检测C程序中的任务并行区域、流水任务并行区域以及数据并行区域。本发明提出一种动静态结合的检测方法,该方法能够在得到以函数和循环为单元的程序调用图的基础上,进一步动态分析程序各部分各种粒度并行的可能性。
产业化前景描述:如何对计算机程序进行并行化处理,以节省大型和复杂问题的解决时间?如何确定并行区域,以实现程序的并行化?如何进行静态分析和动态分析,以提高程序分析的准确性和可读性?如何结合源代码分析和二进制分析,以更全面地分析程序结构?如何提高数据可读性,减少程序分析的复杂性,并提高程序分析的准确性和可控性?
本专利提出了一种新的方法,通过自顶向下地分析C程序,以函数和循环为分析单元,能够全面地统计出各个单元之间的调用关系和开销,并输出程序调用图,实现可视化操作。同时,在程序调用图的基础上进行任务/流水/并行区域的分析,能够有效地识别出程序中各种粒度的并行区域。相比传统方法,该方法能够输出函数之间的调用及依赖关系,还能输出循环乃至一般语句之间的调用及依赖关系,对程序员理解复杂程序以及对程序进行并行化具有重要指导作用。
发明人:刘鹏,黄心忆,李宏亮
申请日期:2018-11-23
授权日期:2020-12-04
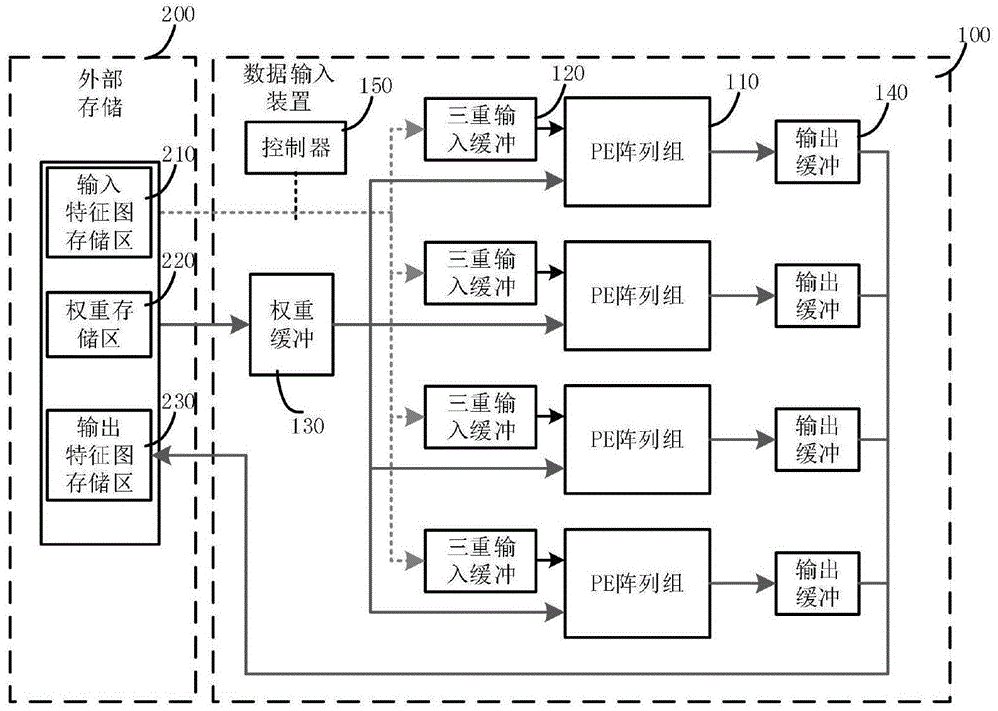
本专利对应产品、技术优势、性能指标:本发明提供了一种深度神经网络硬件加速的数据输入装置,包括PE阵列组、三重输入缓冲、权重缓冲、输出缓冲和控制器;三重输入缓冲与PE阵列组一一对应的相连,且PE阵列组和输出缓冲一一对应的相连;每个三重输入缓冲通过总线与输入特征图存储区相连;控制器分别与输入特征图存储区以及每个三重输入缓冲相连;权重缓冲通过总线与权重存储区相连,且权重缓冲与每个PE阵列组相连;每个输出缓冲通过总线与输出特征图存储区相连。本发明还提供一种利用上述装置进行的深度神经网络硬件加速的数据输入方法,通过对三重输入缓冲的设计,实现数据传输时时延隐藏的目的的同时使数据重叠的部分可以直接复用,提高数据的复用率。
产业化前景描述:如何利用深度学习技术在机器学习中提取更复杂的特征表达,并提高权重学习的有效性?如何设计相应的加速器,以解决神经网络计算和访存密集的问题,实现实时应用?如何提高神经网络加速器的能效,利用片外存储到片上缓冲的数据复用?
本发明采用三重输入缓冲机制,利用多块缓冲实现数据传输时时延隐藏,并通过设计使数据重叠的部分可以直接复用,提高数据的复用率。同时,通过设计自适应移位取数单元,能够支持不同卷积核尺寸和不同步长下的数据高效读取,并最大限度复用从三重输入缓冲到处理单元的数据。
发明人:刘鹏,刘勇,辛愿
申请日期:2013-04-18
授权日期:2016-03-02
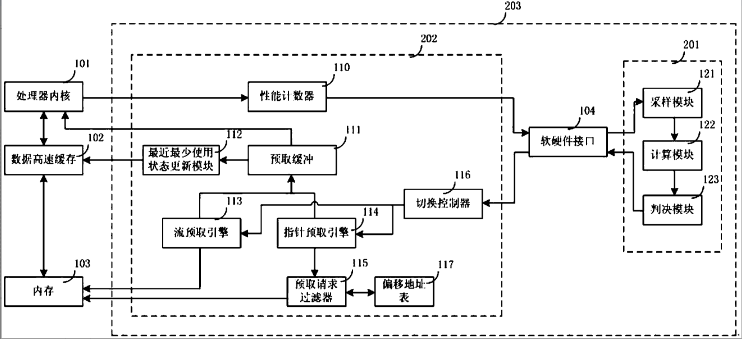
本专利对应产品、技术优势、性能指标:本发明公开了一种多模式数据预取装置,包括处理器内核、数据高速缓存、内存和多模式预取系统;所述多模式预取系统包括软件性能监视器和硬件预取系统装置;软件性能监视器包括采样模块等模块;硬件预取系统包括性能计数器等模块;数据高速缓存分别与处理器内核、最近最少使用状态更新模块和内存信号连接,内存还与流预取引擎信号连接,内存还通过预取请求过滤器与指针预取引擎信号连接;预取缓冲分别与最近最少使用状态更新模块、流预取引擎、指针预取引擎和处理器内核信号连接;性能计数器分别与处理器内核和软硬件接口信号连接,软硬件接口还与切换控制器信号连接;偏移地址表与预取请求过滤器信号连接。
产业化前景描述:如何提高嵌入式处理器的存储系统性能,降低访问片外存储器的次数,提高处理器的性能和效率。其中,数据预取机制是一种可行的方法,但是不同的应用程序拥有不同的数据结构,需要重新设计针对链式数据结构访问特征的预取引擎。为处理器添加多个预取引擎组成多模式预取系统,是解决上述问题的一种有效途径,但是需要考虑很多因素,如硬件和功耗的开销、预取引擎之间的竞争等。
本发明提供了一种多模式数据预取装置及其管理方法,可以根据当前应用特性,自适应地在流预取模式、指针预取模式和无预取模式这三种工作状态下切换,以优化处理器存储系统,兼顾性能和功耗方面的平衡。通过对指针预取的过滤,可以降低无效预取的比例,节省处理器总线带宽资源。同时,通过对高速缓存替换机制的改进,还可以降低无效预取对高速缓存的污染。
发明人:刘鹏,沈炳锋,王维东,方兴,李顺斌,郭俊,邬可俊
申请日期:2014-04-25
授权日期:2017-01-25
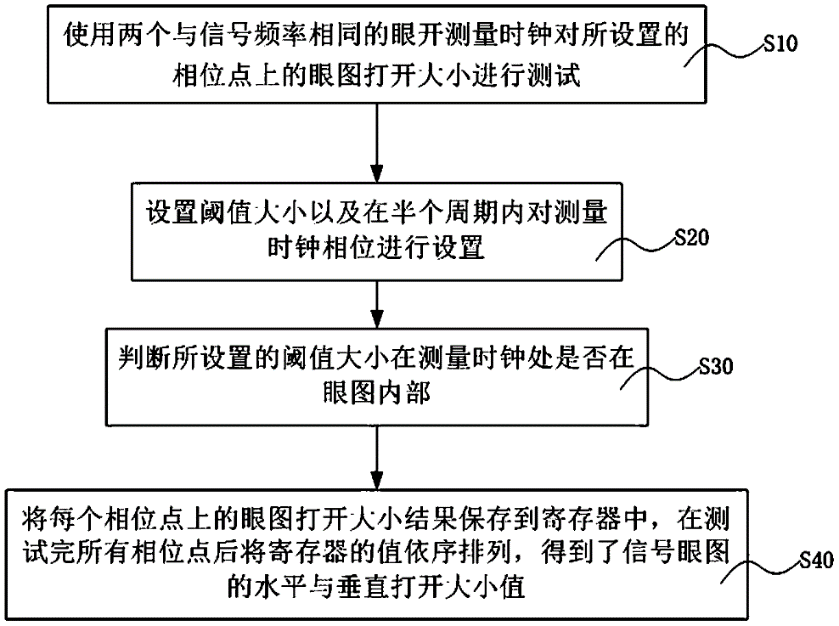
本专利对应产品、技术优势、性能指标:本发明提供的眼开监视器装置在实现信号眼图测试时,使用两个与信号频率相同的眼开测量时钟对所设置的相位点上的眼图打开大小进行测试;设置阈值大小以及在半个周期内对测量时钟相位进行设置;判断所设置的阈值大小在测量时钟处是否在眼图内部,满足在眼图内部的最大阈值便是该时钟相位点处的眼图打开大小;将每个相位点上的眼图打开大小结果保存到寄存器中,在测试完所有相位点后将寄存器的值依序排列,得到了信号眼图的水平与垂直打开大小值。与现有技术相比,本发明提出的眼开监视器电路装置具有无需进行初始时钟与数据的同步操作,测试过程设置与测试结果记录由数字控制模块自动完成,可获得一个周期内信号眼图打开大小信息的特点。
产业化前景描述:如何提高嵌入式处理器的存储系统性能,降低访问片外存储器的次数,提高处理器的性能和效率。其中,数据预取机制是一种可行的方法,但是不同的应用程序拥有不同的数据结构,需要重新设计针对链式数据结构访问特征的预取引擎。为处理器添加多个预取引擎组成多模式预取系统,是解决上述问题的一种有效途径,但是需要考虑很多因素,如硬件和功耗的开销、预取引擎之间的竞争等。
本发明提供了一种多模式数据预取装置及其管理方法,可以根据当前应用特性,自适应地在流预取模式、指针预取模式和无预取模式这三种工作状态下切换,以优化处理器存储系统,兼顾性能和功耗方面的平衡。通过对指针预取的过滤,可以降低无效预取的比例,节省处理器总线带宽资源。同时,通过对高速缓存替换机制的改进,还可以降低无效预取对高速缓存的污染。
发明人:刘鹏,谢向辉,史航,王维东,郭俊,李顺斌,邬可俊,方兴,吴东,江国范
申请日期:2015-01-22
授权日期:2017-11-24
本专利对应产品、技术优势、性能指标:本发明公开了一种应用于高速背板芯片间电互连系统的网格编码调制方法,该方法涉及应用于高速背板芯片间电互连系统的网格编码调制技术,该方法通过信道编码和信号调制的协同设计,可以在既不增加信道频带宽度,也不降低有效信息传输速率的情况下获得编码增益,提高芯片间串行单链路的性能。该系统发送端包括数据并转串、网格编码调制、前向反馈均衡器,其中网格编码调制采取卷积编码和四电平脉冲幅度调制相结合的手段;接收端包括连续时间线性均衡器、判决反馈均衡器、时钟数据恢复、软判决维特比译码、数据串转并,其中判决反馈均衡器滤波器的系数更新基于软判决维特比译码后的纠错信号。
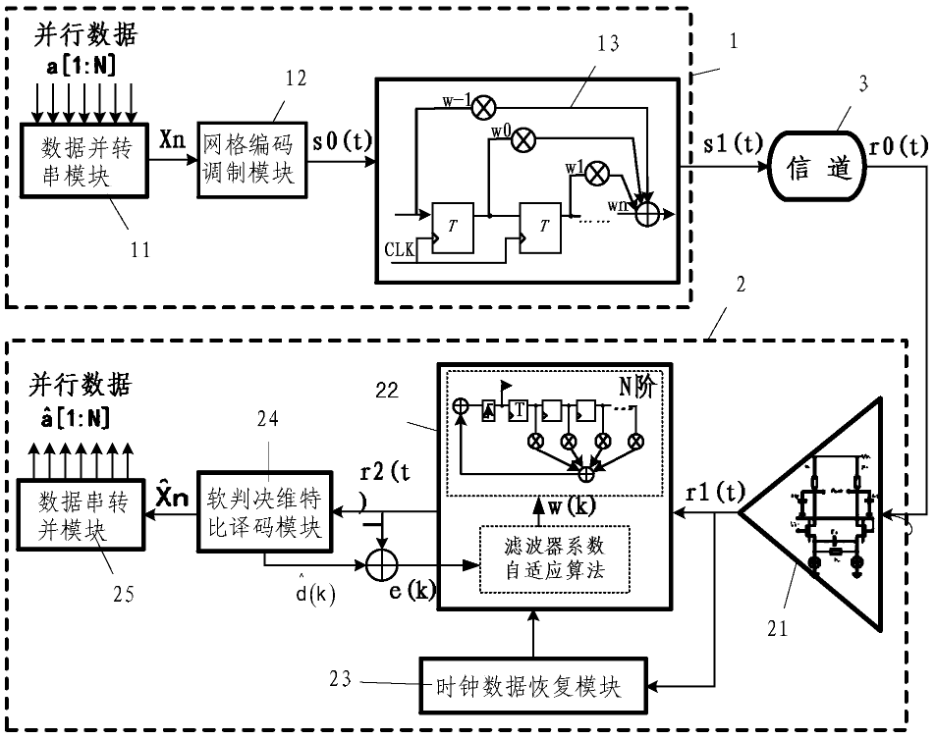
产业化前景描述:如何在高速串行电互连接系统中引入纠错编码技术,降低系统误码率,提高数据传输速率和系统性能?
本专利提出了一种高速串行链路系统,利用卷积编码和四电平脉冲幅度调制相结合的网格编码调制,通过引入卷积编码在接收端进行纠错,同时采用高阶调制使系统带宽保持不变,从而提高了高速背板电互连系统的抗干扰能力,与未编码的两电平串行链路系统相比,本系统可获取2.55dB的编码增益。此外,本发明还提供了相应的发送端编码调制和接收端软判决维特比译码方法,以及使用TCM-PAM4进行网格编码调制的高速背板电互连系统的实验结果。
发明人:刘鹏,辛愿,刘勇,于绩洋,黄巍
申请日期:2013-04-11
授权日期:2016-01-20
本专利对应产品、技术优势、性能指标:本发明公开了一种线程感知多核数据预取自调方法;包括以下步骤:a、动态反馈信息统计:通过硬件计数器统计各线程的存储访问行为和预取行为信息;b、指标计算:根据动态反馈信息统计的结果计算各线程用以衡量其竞争程度的访存特性和预取特性指标;c、线程分类:根据各线程的访存特性指标和预取特性指标对线程进行分类;d、预取调节:根据线程分类结果进行预取模式和激进度的调节;e、攻击预取过滤:对可能造成共享数据无效化的预取请求进行过滤。
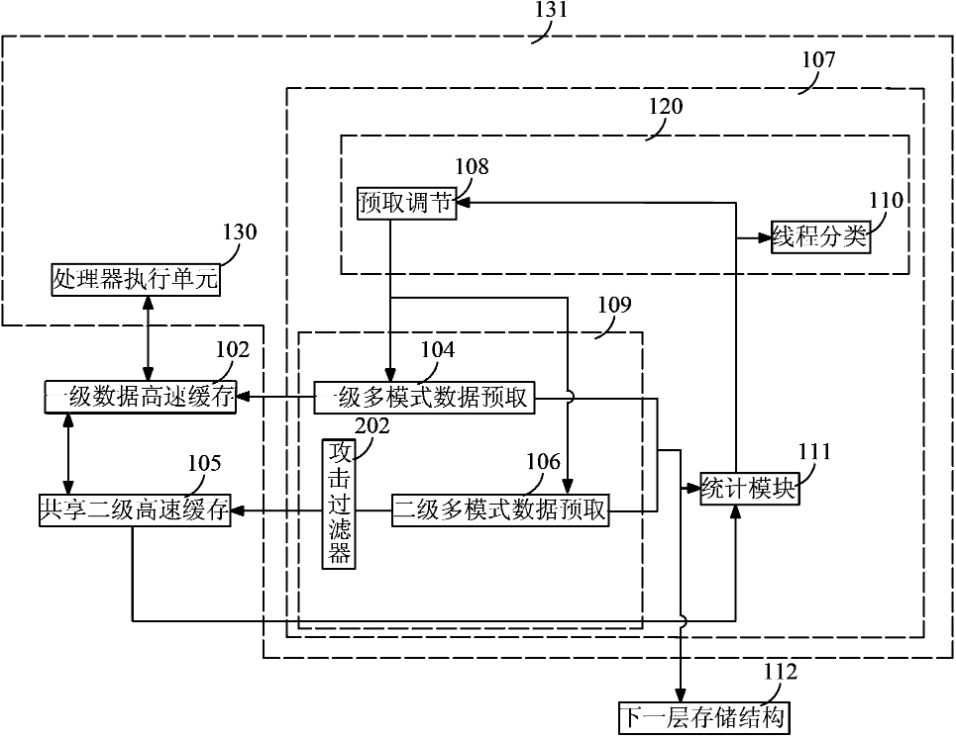
产业化前景描述:在多核处理器系统上,预取技术的应用存在着资源竞争和性能损失的问题,需要考虑与应用相关的处理器核间一致性和多线程应用,以有效管理共享资源并减少预取导致的资源竞争。同时,预取请求可能会影响其他线程私有高速缓存的命中情况,需要考虑线程的协作方式和相互独立性来进行自适应调节。
本发明提出了一种线程感知多核数据预取自调方法,解决了预取导致的线程间数据无效化问题,提高了私有数据cache命中率。同时,该方法还可以减少线程间预取对共享资源的竞争,提高预取性能,降低整体系统的能量时间积。
发明人:刘鹏,周英
申请日期:2016-04-16
授权日期:2018-02-27
本专利对应产品、技术优势、性能指标:本发明公开了一种基于机器学习的预取能效优化自适应装置及方法,本发明的结合机器学习的动态调整预取配置的方法,能够根据应用的特征最大化预取能效。具体如下:a、提取程序特征:通过硬件计数器提取应用程序在运行时的存储访问行为及预取相关行为信息,作为程序特征观测量;b、构建训练数据集:根据程序特征提取的结果,选择与预取能效最相关的特征及达到最大能效时预取的配置,作为一个有效数据;c、训练学习模型:给定程序的特征观测量及对应的最优预取配置作为模型的输入,采用机器学习的算法训练学习模型;d、动态预测预取配置:学习模型根据新的应用程序运行时收集程序特征观测量对程序进行分类,预测预取的配置最大化能效。
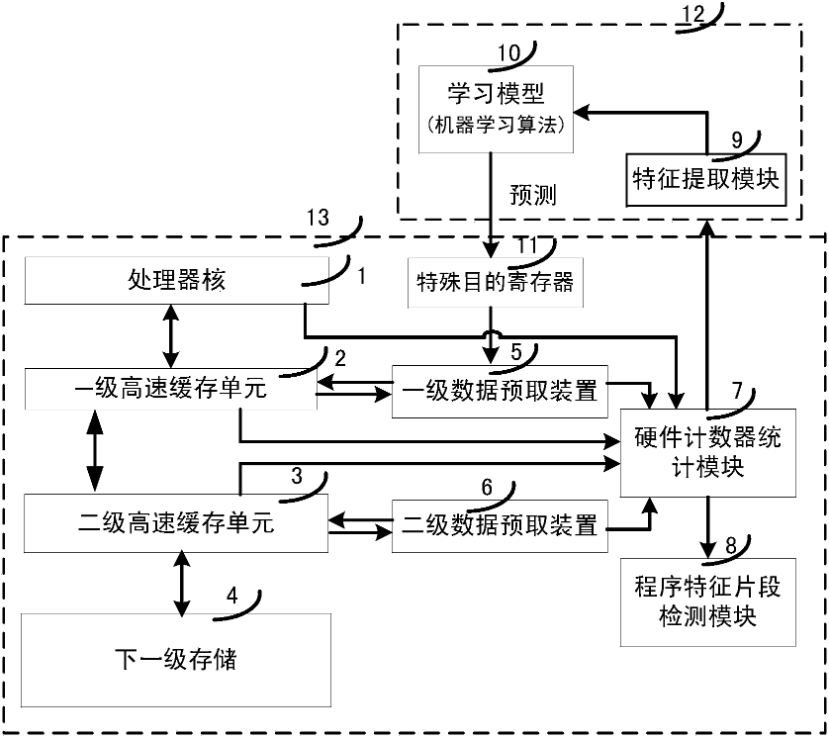
产业化前景描述:如何利用机器学习方法来优化处理器系统中的硬件预取,以提高预取的效果和降低功耗,解决非线性问题和提高预取的准确性,同时考虑预取的动态性和能效性,缩小预取搜索空间,并实现动态预测预取的配置。
该专利文本提出了一种基于机器学习的算法来预测应用程序的预取配置,并实时调整预取的激进程度或及时关闭预取,从而提高预取的能效。此外,通过定时检测程序的访问高速缓存缺失率及程序性能及预取的命中率等的变化来判断当前程序的访存行为是否发生变化及当前的预取配置是否有效,从而实现实时准确的调整。该技术不需要更改硬件实现,可在现有的硬件预取机制上采用软件实现选优。
云计算与大数据服务;人工智能系统服务;工业控制计算机及系统制造; 信息处理和存储支持服务;集成电路制造;通信设备、雷达及配套设备制造
□样品、实验阶段
□小批量生产、工程应用阶段
☑试生产、应用开发阶段
专利许可、转让、作价投资等,具体详谈。
刘鹏教授,博士生导师,围绕新兴应用对于计算系统的高性能、高能效和高可靠性需求,专注于处理器设计和硬件安全。负责完成国家863项目、国家自然科学基金、基础预研、霍英东教育基金等10余项国家纵向项目,研究涵盖应用算法、微架构、电路三个层次,提供实用有效的解决方案。2003年主持设计国内首款RISC/DSP媒体数字信号处理器(“浙大数芯”),浙大数芯系列IP核包括:媒体数字信号处理器、SerDes IP、32位微处理器CPU IP核,集成浙大数芯处理器IP核的系统芯片量产销售超过2000万颗。发表学术论文170余篇,授权中国发明专利50余项,授权发明专利转让1项,荣获2020年度浙江省科技进步二等奖,系统创造性的研究成果发表于IEEE Trans. Computers, ACM TACO, TVLSI, CHES, ISCA等国际顶级期刊和顶级会议。中国计算机学会高级会员, IEEE CS会员,IEEE SSCS会员,A-SSCC, VLSI-SOC 技术委员会委员,信息技术创新工作委员会产业成熟度工作组委员,制定信息技术应用创新信息产品成熟度评估体系芯片团体标准。
浙大工研院成果转化服务中心,0571-88982927。
注:所有成果技术资料来自研究团队,未经授权,请勿转载!
咨询授权请联系:0571-88982927
电话:0571-88982935
传真:0571-88982801
地址:浙江省杭州市西湖区西园八路3号浙大紫金科创小镇E1楼六楼
