
1.成果名称及简介
(1)成果名称:SpecVLM(无损加速视频理解大模型推理技术)
(2)成果关键词:视频理解大模型、推理加速、无损、剪枝
(3)成果简介:
视频语言大模型由于巨量的模型参数和输入规模,在推理阶段面临性能挑战。本成果(SpecVLM)解决了现有加速技术固有的生成质量损失问题,实现了无损地加速视频语言大模型的推理。同时,本成果结合推测解码技术显著降低了解码延迟,实现了高推理加速比,为计算资源受限的应用场景赋能。
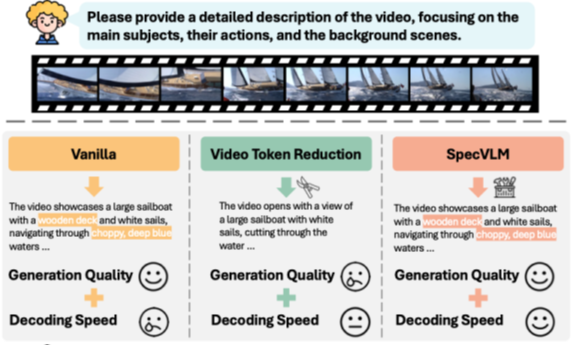
如图所示,从左到右:
(1)原生的视频理解大模型:虽然生成质量较优,但是由于庞大的显存和视频开销,导致推理速度很慢。
(2)传统的剪枝加速技术:虽然一定程度提高了推理速度,但是以生成质量为代价,且无法获得显著加速。
(3)本成果(SpecVLM)技术:通过结合推测解码技术,在参数+视频输入两个维度联合优化,没有任何质量损失的同时,实现了最高达2.68倍的推理解码加速比。
实例展示:(保证了模型的输出质量,同时获得显著加速)

(2.68x推理解码加速)
2.知识产权情况
(1)知识产权类型:
✅专利 □软著 □技术秘密 □植物新品种 □集成电路布图设计 □其他:
(2)具体清单:
专利成果名称:视频大模型的推测解码方法、装置和终端设备
专利号:202511079509.4
申请时间:2025年8月5日
发明人:李环 季奕丞 张俊寿 黎但 陈刚 陈珂 谢钟乐 骆歆远
权利人:浙江大学,杭州高新区(滨江)区块链与数据安全研究院
3.技术领域/行业分类
多模态大模型、视频理解大模型、AI Infra
4.技术/行业痛点
行业痛点:视频语言大模型(视频理解大模型)大多采用序列式的视觉特征表示,将视频中采样的帧通过编码形成数以万计的视觉词元(Visual Token),并与文本提示词一同输入模型,来生成高质量的输出。然而,随着视频长度的逐渐增长,这种架构在预填充(Prefilling)和解码(Decoding)阶段都带来了巨大的计算与内存开销。如此长的序列不仅导致模型内部注意力机制在预填阶段的计算量呈现平方级增长,还加剧了解码阶段中因自回归(Autoregressive)结构所引起的内存带宽瓶颈。随着解码阶段的进行,键值(Key-Value)缓存不断线性增长,在每个时间步内,都需要连同模型参数一起被加载到GPU SRAM 上,从而大大增加了模型的推理延迟。
技术痛点:当前针对视频理解大模型进行效率优化的技术主要采取“剪枝(Token Pruning)的方式,直接地将输入大模型的视觉信息进行筛选,这就直接导致了模型最终输出的文本质量下降、语义折损。当前的技术缺乏无损的加速方案。
5.解决方案与技术优势
解决方案:
整体而言,本研究从参数和视频Token两个方面联合优化:
(1) 推测解码技术:减少模型推理的参数传递
(2) 剪枝技术(Token Pruning):减少视觉输入端的开销
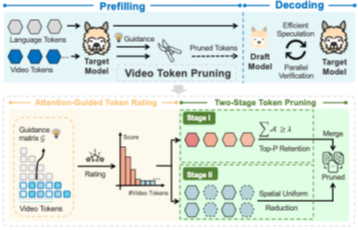
基于词元剪枝的推测解码增强框架。在预填充阶段,通过目标模型的注意力指导,为草稿模型实现视觉词元剪枝。在解码阶段,草稿模型高效地产生预测,由目标模型并行验证,保证原有的输出分布。剪枝模块具体步骤:首先基于目标模型的注意力矩阵,计算文本对视觉词元的平均注意力分数。此后,根据分数将输入词元划分为“高信息词元”和“低注意力词元”,采用两阶段剪枝方案。(i)高信息词元:根据注意分数的比例,采用Top-P法保留与输入相关的信息。(ii)低注意力词元:在空间上均匀地选择性保留,来保持一定的空间结构。
技术优势:
现有技术的核心缺陷体现在两方面:首先,词元剪枝常常导致模型的精度损失和生成质量下降问题。由于词元剪枝是一次性的,不可逆的,因此在推理任务中,剪枝后模型将无法保证原本的生成概率分布。在需要密集视觉信息的场景下,这一挑战更加严峻,且往往决定了模型的能力边界。其次,现有技术缺乏对解码阶段的优化。现有的剪枝方法局限于关注预填充阶段,仅仅通过降低输入序列长度来减少后续解码的延迟,而这类方法对解码过程的加速效果是受限的。深层原因在于,解码过程收到内存带宽瓶颈的限制,需要在模型参数和KV缓存进行协同优化,简单的剪枝策略并不能降低模型参数在GPU上传输的开销。
因此,本成果的技术优势在于没有任何模型质量损失以及优异的加速比。
6.课题资助与所获奖励
(1)课题项目:浙江省重大项目《面向大模型训练的多模态数据治理策略研究》
7.技术成熟度
□构思 □研发 ✅样品 □小试 □中试 □产业化、推广 □其他:
8.应用前景
(1)适用领域:多模态大模型、视频理解大模型、AI Infra
(2)目标客户:大型互联网企业、电信企业、AI Infra创业公司、AI应用创业公司
(3)消费群体:
(4)商业计划及市场前景:
9.合作转化方式
✅普通许可 ✅排他许可 □独占许可 □转让 □作价入股
✅技术开发 ✅技术咨询 ✅技术服务 □其他:
10.意向合作方
□国有企业 ✅上市公司 ✅行业龙头企业 □其他:
11.意向合作金额
✅10万—50万 ✅50万—100万 ✅100万—500万
□500万—1000万 □1000万以上 □其他金额: □ 面议
12.科研团队
(1)项目负责人:姓名 李环 ,职务职级 计算机学院百人计划研究员
(2)科研团队的简介
科研团队介绍:浙江大学计算机学院数据库与数据智能实验室在陈刚教授带领下,深耕数据库、大数据与大模型基础设施领域。团队承担了国家重点研发计划、863项目、国家自然科学基金等20余项国家级课题,并与网易、阿里巴巴建有联合研究中心。研究方向聚焦于批流混合时态大数据实时处理、云数据库管理及互联网大数据处理技术。团队研发了神通数据库、SMARTDB、TableGPT等系统,获国家科技进步二等奖2项,教育部及浙江省科技进步一等奖3项。发表学术论文200余篇,近五年CCF A类论文100余篇,并获得VLDB 2014/2019、SIGMOD 2023最佳论文奖等。成果应用于金融、电信、国防等关键领域,在网易产品中支持超10亿用户、100PB数据处理,神通数据库已在千余套国家重点系统中实现对国外产品的替代。
专利负责人介绍:李环,浙江大学计算机学院“百人计划”研究员、博士生导师,曾任丹麦奥尔堡大学计算机系助理教授及瑞士EPFL访问学者。长期聚焦“资源高效、以数据为中心的人工智能方法和应用”,主要方向包括人工智能数据准备、大小模型高效推理与部署、时空大数据智能等。已在CCF-A等顶级会议发表高水平论文70余篇,获三项重要国际会议最佳论文或提名奖,成果被 Informa、MarkTechPost、OS China等媒体报导。主持国家级项目3项、省重大项目1项、欧盟地平线项目1项及多项校企合作,研究成果广泛应用于物联网、社会服务及互联网推荐等领域。2020年获欧盟 “玛丽·居里”学者独立研究基金、2022年入选国家级青年人才计划、2024年获国际计算机学会中国新星奖提名(全国3人)、SIGMOD China新星奖。担任中国计算机学会数据库专委会//执行委员,中国人工智能学会智能服务专委会//委员。
13.联系方式
浙大工研院成果转化服务中心,0571-88982927。
电话:0571-88982935
传真:0571-88982801
地址:浙江省杭州市西湖区西园八路3号浙大紫金科创小镇E1楼六楼
